
SO-VITS-SVCが登場したと思ったらRVCというまた新しいのが登場したので少し触ってみる。
まずRVC WebUIをダウンロードしないと話が進まない。
RVCのHugging FaceからRVC-beta.7zをダウンロードする。
3GBほどあるので気長にダウンロードが終わるまで待とう。

またGitやPythonわかるぜという人は、GitHubのレポジトリを確認しよう。

ダウンロードした適当な場所に解凍し、RVC-betaファルダ内のgo-web.batを実行する。
すると、勝手にブラウザが立ち上がるか新規タブが開かれる。
立ち上がらないか新規タブができない場合は、http://127.0.0.1:7865/にアクセスすればいい。
環境によっては、コマンドプロンプトがすぐに閉じてしまい起動できない場合があるが、そのときはMicrosoft Visual C++ 再頒布可能パッケージをインストールすれば起動できるだろう。
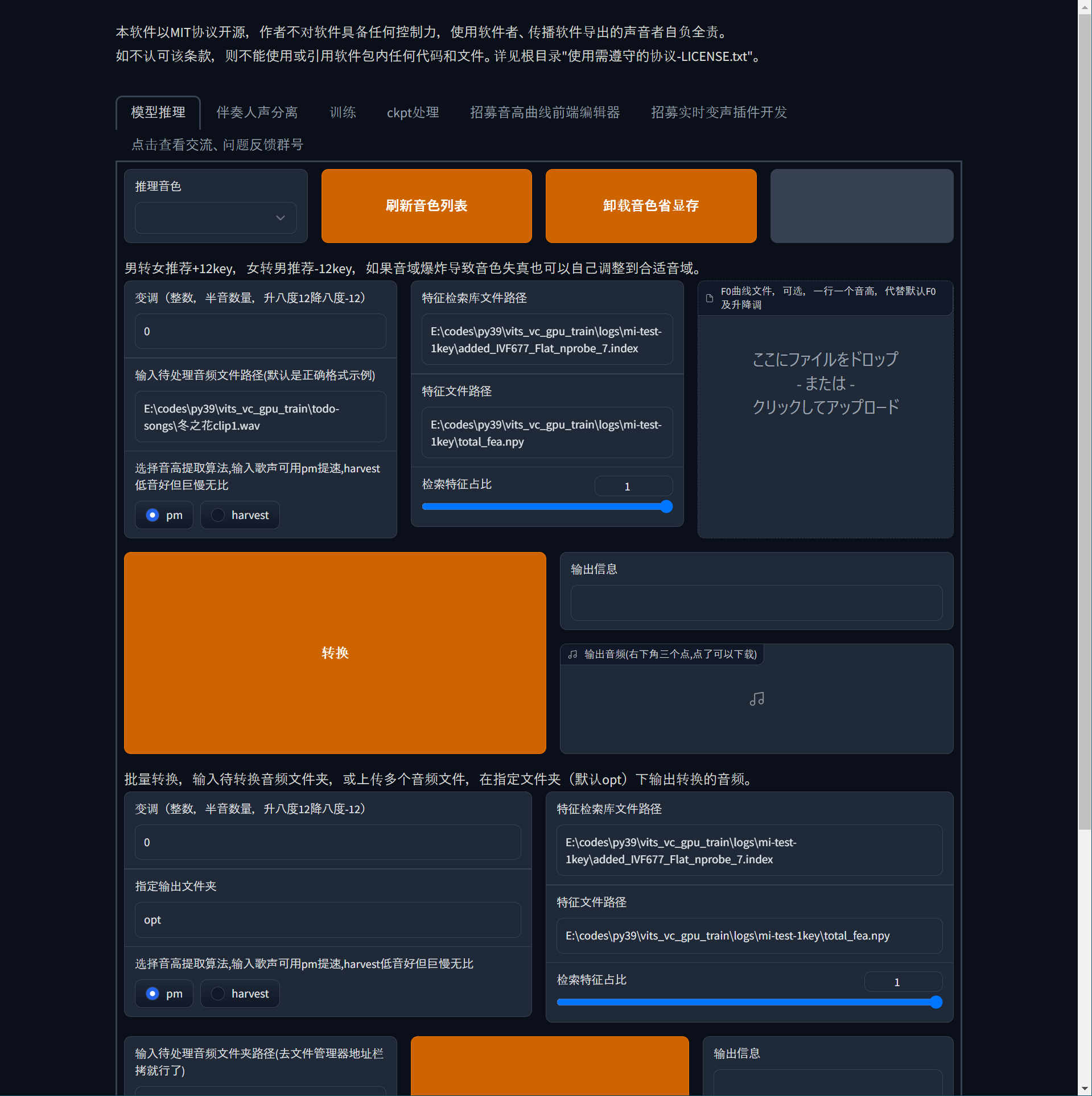
以下のようなUIが表示されていれば問題はない。
基本的に言語は中国語である。
更新
更新があるので、以下のリンクからファイルをダウンロードする。
ダウンロードするファイルは、AssetsのupdateYYYYMMDD.zipである。
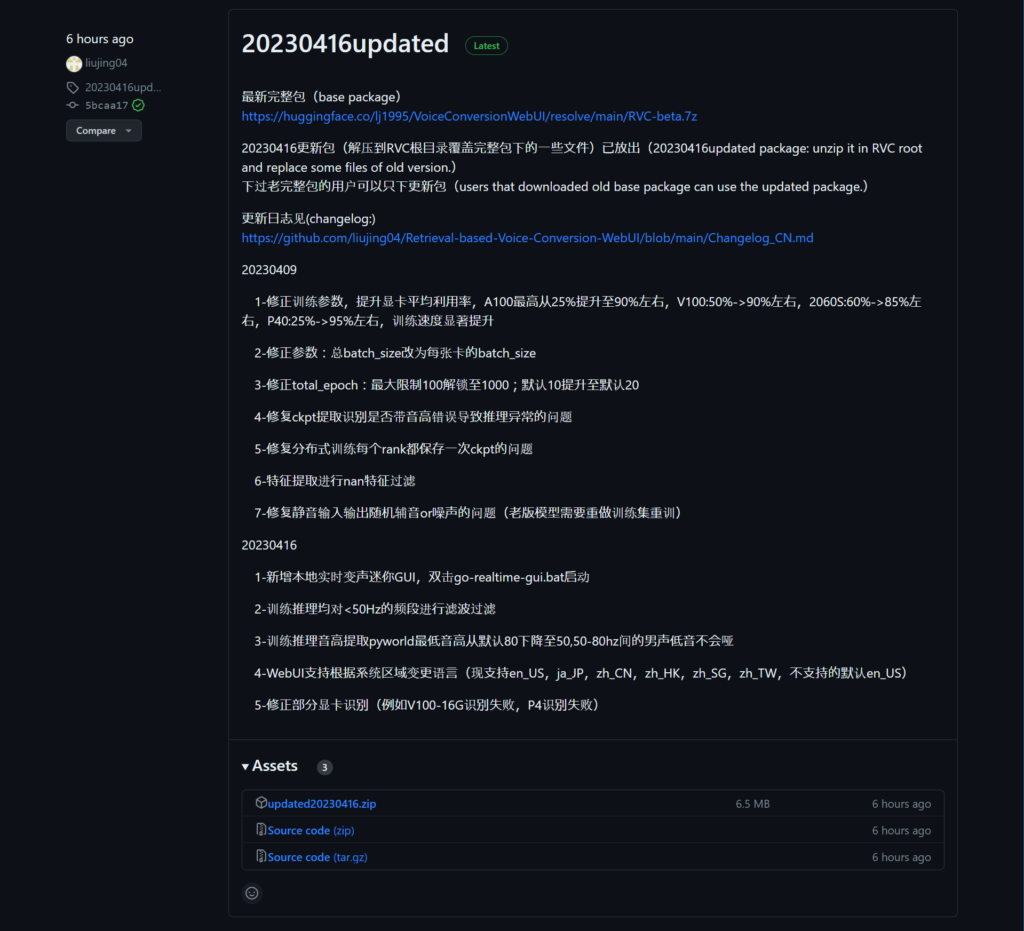
ダウンロードしたファイルを展開し、展開したフォルダ内にある全ファイルをRVC-betaに突っ込む。
更新があるたびに、これを行う。差分だけ配布してくれるのでありがたい。
学習
まず、学習を行う。
上部のタブから训练を開く。
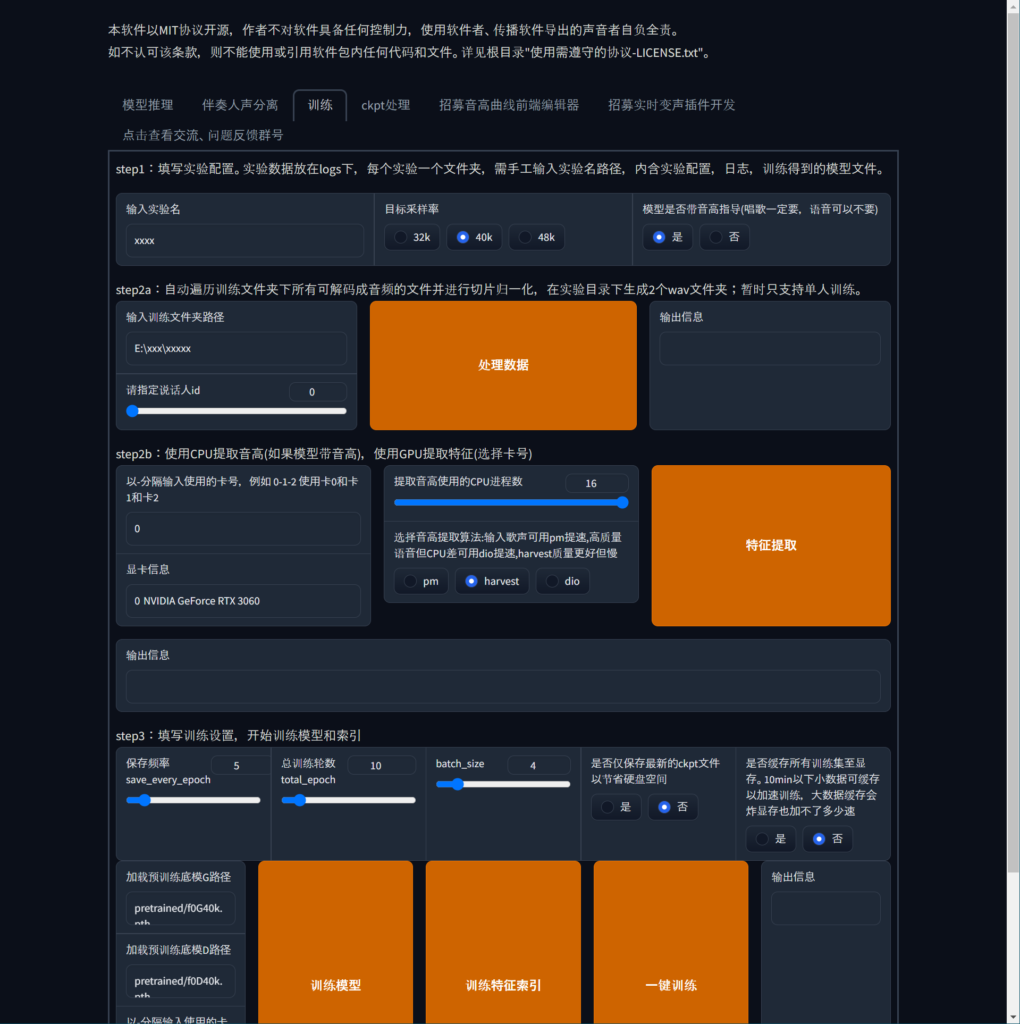
step1から順番に必要な情報を入力していく。
step1

输入实验名
学習対象名などを自分がわかりやすい名前を入力。
今回は陸八魔アルの音声を学習させるためAruとする。
目标采样率
使用するサンプリング周波数を選択する。
デフォルトの40kで問題ないだろう。
模型是否带音高指导
声以外の音声が入っているか。
今回は入っていないが、デフォルトのまま進める。
step2
输入训练文件夹路径
学習元のデータがあるパスを入力する。
例として今回はこのようになった。 W:\Workspace\RVC-beta\Aru
请指定说话人id
IDを指定する。基本的には0のまま。
处理数据
ここを押すと、サンプリング周波数に音声データが変換される。
進行状況は、横の输出信息から確認できる。end preprocessと表示されていれば、処理が終了したことになる。
step2b
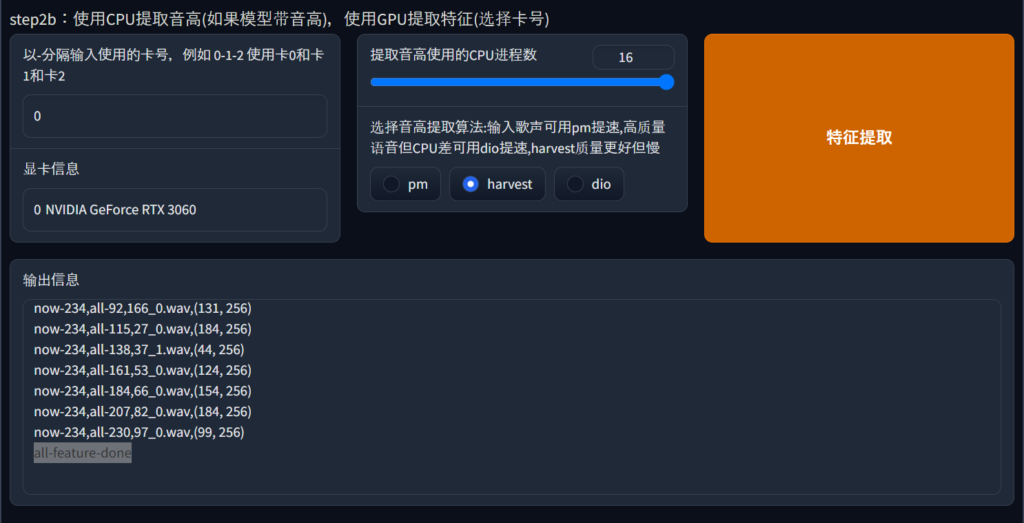
以-分隔输入使用的卡号,例如 0-1-2 使用卡0和卡1和卡2
基本的には0のままでよい。
グラフィックボードが2枚刺しなんかの人は複数指定ができる。
显卡信息
学習時に利用されるグラフィックボード名が表示される。
私は3060を利用しているので、NVIDIA GeForce RTX 3060と表示される。
提取音高使用的CPU进程数
CPUで利用するスレッド数を指定する。
自分が利用しているCPUのスレッド数に合わせて変更する。
そして、ピッチ抽出アルゴリズムを選択をpm harvest dioの中から選択する。pmは、高速化可能、高音質だがCPUが貧弱。harvestは、高品質だが遅い。dioは、高速化可能。
Deepl翻訳でもよくわからなかったので、とりあえずharvestを選択した。
特征提取
ここを押すと、音声データのピッチが抽出される。
進行状況は、下の输出信息から確認できる。all-feature-doneと表示されていれば、処理が終了したことになる。
step3

保存频率 – save_every_epoch
モデルを保存するepochの間隔。デフォルトで問題ないだろう。
总训练轮数 – total_epoch
何epochで学習を終了させるか。
とりあえず68にした。
batch_size
なるべく大きめが良いがスペックによってはクラッシュするので、適度に調整をする。
是否仅保存最新的ckpt文件以节省硬盘空间
ハードディスクの容量を節約するために、最新のckptファイルのみを保存するかどうか。
デフォルトで問題ない。
是否缓存所有训练集至显存。10min以下小数据可缓存以加速训练,大数据缓存会炸显存也加不了多少速
トレーニングセットをビデオメモリにキャッシュするかどうか。10分以下の小さなデータはキャッシュしてトレーニングを高速化できるが、大きなデータはキャッシュするとビデオメモリが圧迫され、あまり高速化できない。
デフォルトで問題ない。
加载预训练底模G路径・加载预训练底模D路径
ここには、選択したサンプリング周波数と同じ事前学習モデルのパスを入力する。
RVC-betaのディレクトリ内のpretrainedフォルダに事前学習モデルがある。
训练模型
ここを押すと、学習が始まる。
total_epochで入力したepoch数になるまで学習が行われる。
学習が完了すると、RVC-betaのディレクトリ内のweightsフォルダにpthが保存される。
進行状況は、右の输出信息から確認できる。
训练特征索引
ここを押すとインデックスの学習始まる。
インデックスの学習により、単純な学習より学習元の声質に近づけることができる。
進行状況は、右の输出信息から確認できる。
一键训练
ここを押すと、step2aからstep3の処理が一括で実行される。
すでに順番に処理を行った人は押さなくていよい。
変換
実際に音声を変換してみる。
上部のタブから模型推理を開く。刷新音色列表を押して、モデルリストを更新する。
すると、推理音色から先程学習させてできたモデルがあるので選択する。
今回は、Aru.pthを選択する。
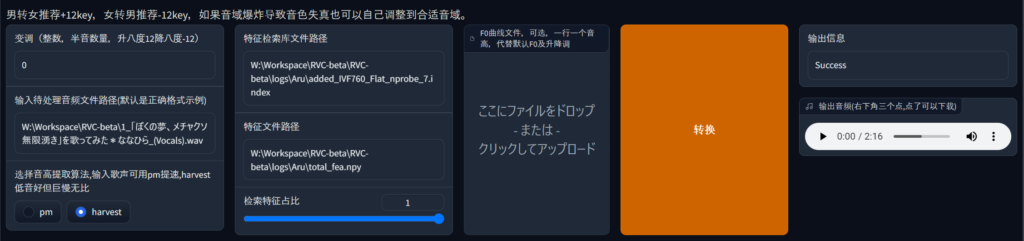
变调で変更するキーを整数で入力。
今回はキーの変更をしないため、0のまま。输入待处理音频文件路径(默认是正确格式示例)に変改したい音声ファイルのパスを入力する。またはF0曲线文件,可选,一行一个音高,代替默认F0及升降调の下、ここにファイルをドロップ- または -クリックしてアップロードにファイルを投げる。选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比でpmかhervest、どちらかを選択する。pmは処理が高速。harvestは、pmくらべ処理速度は遅いが高品質。らしい。
特征检索库文件路径にindexファイルのパスを入力する。indexファイルはRVC-betaのディレクトリ内のlogs > 話者名 フォルダにある。今回は、added_IVF760_Flat_nprobe_7.indexというファイル名であった。特征文件路径にnpyファイルのパスを入力する。npyファイルは同じくRVC-betaのディレクトリ内のlogs > 話者名 フォルダにあるtotal_fea.npyになる。检索特徴征占比で、元音声の声質をどのぐらい再現するかで調整する。
转换を押すと、変換処理がはじまる。
進行状況は、右の输出信息から確認できる。
変換が完了すると、输出音频(右下角三个点,点了可以下载)で変換した音声を確認できる。
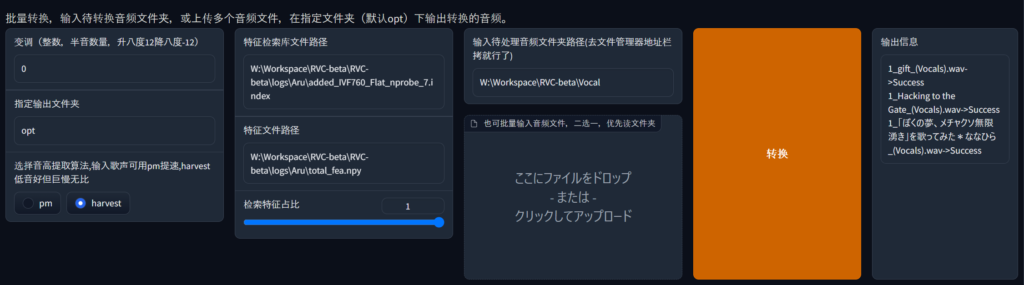
一括変換
一括変換をする場合は下段を利用する。基本的な使い方は一緒だ。指定输出文件夹で出力先のフォルダを指定する。デフォルトでoptファルダに出力される。输入待处理音频文件夹路径(去文件管理器地址栏拷就行了)に変換元のファイルがあるフォルダを指定する。または也可批量输入音频文件,二选一,优先读文件夹の下にあるここにファイルをドロップ- または -クリックしてアップロードに複数ファイルを投げることもできる。
转换を押すと、変換処理がはじまる。
進行状況は、右の输出信息から確認できる。
COMMENT - コメント