


やっぱり魚拓を取られるのは、気分が良いものではないと思う。
つぎは、Wayback Machineからの拒否をしてみる。
Contents
robots.txtを無視?
調べていると、Wayback Machineがrobots.txtに従わないようになるかもという記事を発見した。
しかし、上記の記事の投稿年が2017年である。
これ以降に、関連した情報が発表されていない。
断片的な情報で試行してみる。
ブロック方法
いろんなサイトの情報を元に、以下のエージェントをrobots.txtで拒否することにした。
# Wayback Machine Block
User-agent: ia_archiver
Disallow: /
User-agent: archive.org_bot
Disallow: /
User-agent: ia_archiver-web.archive.org
Disallow: /私は、XML Sitemap & Google Newsを利用しているので設定>表示設定のrobots.txt の追加ルールに記述すればrobots.txtを設置しなくても設定が可能であった。

アーカイブ状況
Wayback Machineで、現在どれぐらいアーカイブが保存されているか確認する。
まず、Wayback Machineにアクセスする。
そして、URLを入力する。
すると、いつアーカイブが取られたかがカレンダー上で表示される。
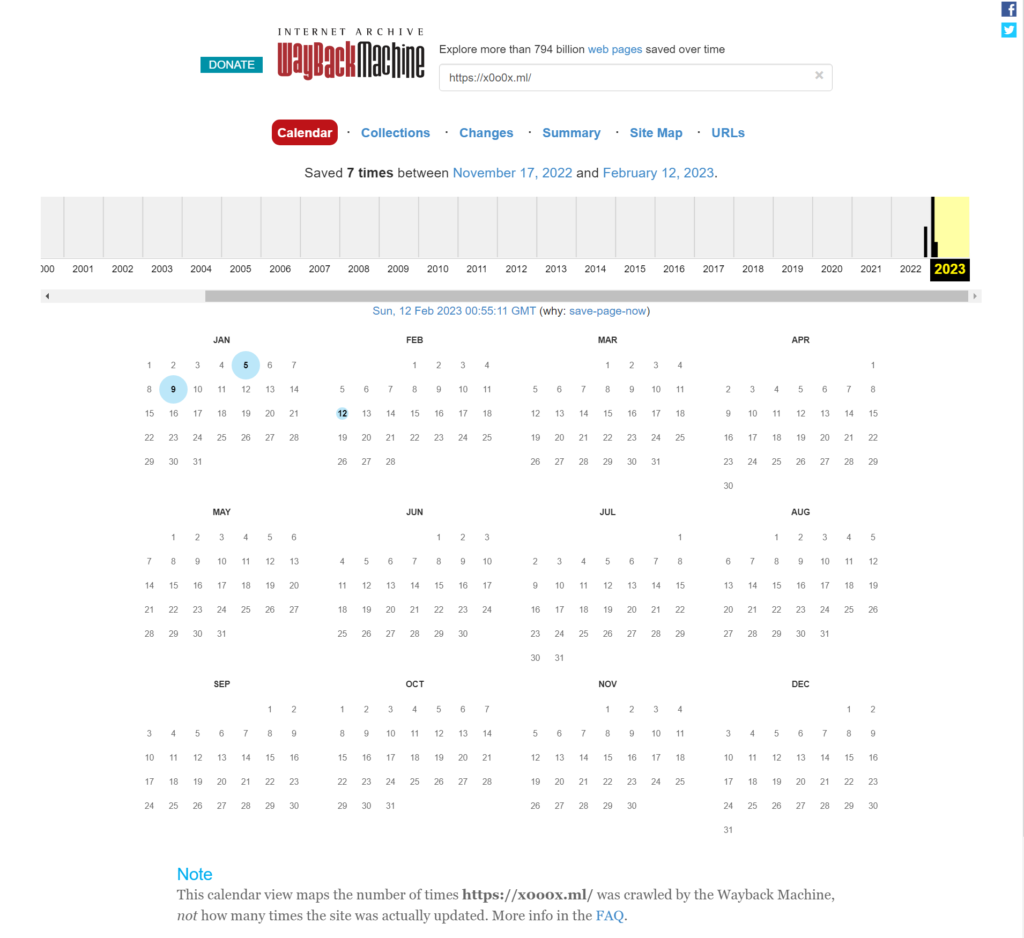
執筆時点で最後に取られたのは、2023年02月12日00時55分11秒(UTC)である。

これ以降にアーカイブが取られていれば、robots.txtの敗北である。
しばらく様子を見よう。
おわりに
過去にWayback Machine公式からエージェント拒否の方法が紹介されていたが、削除されているようだ。
これでだめだったら、.htaccessでのドメイン拒否かJavaScriptによる対策しかなさそうだ。
…😠
😠😠😠

COMMENT - コメント