


なんとなく魚拓を取られるのは、気分が良いものではないと思う。
はじめに、ウェブ魚拓からの拒否をしてみる。
ブロック方法
ウェブ魚拓のQ&Aによれば、robots.txtを設置してMegalodonが取得不可能なパスを指定すればよいとのこと。
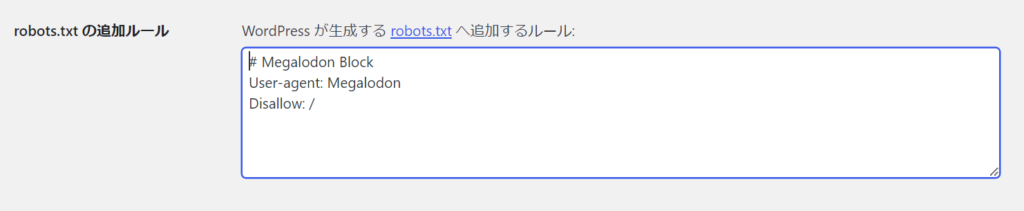
# Megalodon Block
User-agent: Megalodon
Disallow: /私は、XML Sitemap & Google Newsを利用しているので設定>表示設定のrobots.txt の追加ルールに記述すればrobots.txtを設置しなくても設定が可能であった。
なお、記述してもすぐには反映されないよう。
なお、robots.txtはキャッシュしておりますので、変更が反映されるまで長くて3日かかります。
Q&A – ウェブ魚拓
ブロック確認
ブロックされているか確認する。
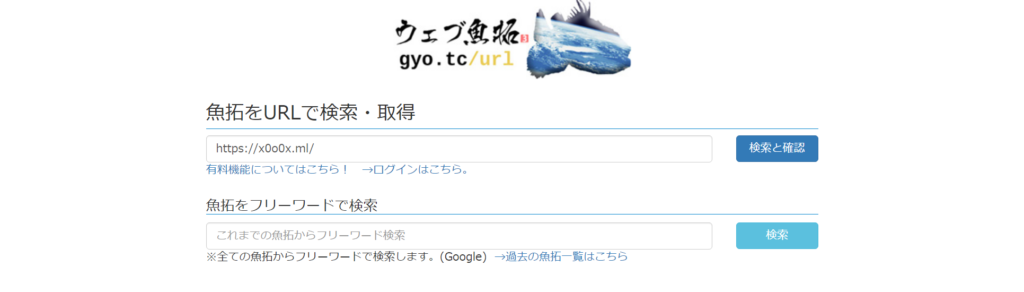
まず、ウェブ魚拓にアクセス。

URLを打ち込んで、検索と確認。
次に、取得。
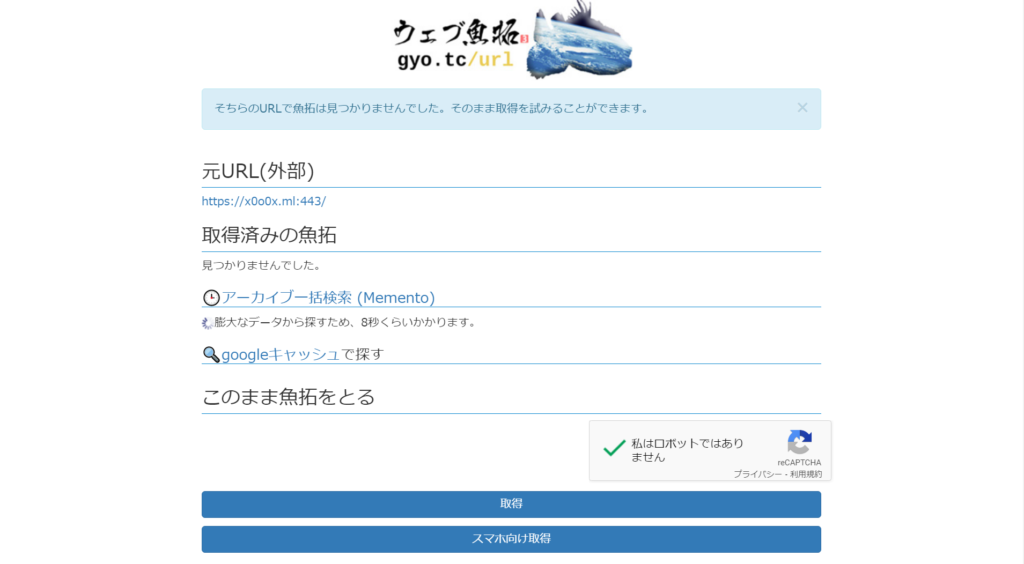
robots.txtによる、アクセス拒否ができている場合は、ブロックされましたと表示される。

おわり
私のサイトに魚拓を取る隙無し!
COMMENT - コメント